CQRS is everywhere but few understand it (Part 1: Origins)
Published:
The Command Query Responsibily Segregation (CQRS) pattern was probably the pattern with the most adepts having a surface-level understanding out of all patterns I’ve seen thus far.
Surface-level understanding is not bad per se; it’s better to have an idea, to be able to circle around it, than to have none; what I mean is that it’s bad when everyone promotes something while not being aware of its deeper roots or meanings, which (might) actually matter.
Of course, ranting people is fun, especially if you have the knowledge and experience to combat their misunderstandings (I’m talking about a group of persons I’ll mention soon). However, I’m not in that position; I’m 22 years old, and I have freshly graduated from a non-important university in a Middle Eastern country. On the other hand, I took the chance to diverge from the mainstream BS thesis subjects (web/desktop apps, AI/ML, IoT, games, etc.) and went back in time to research a topic awkwardly inspired from an idea I stole from a conversation between my thesis coordinator and a colleague (fortunately or not, he didn’t use the idea in the end). That’s what I think might make the opening statement a bit more compelling and help reduce any hint of arrogance if any.
The idea was to write about “proving the role of CQRS”1. Not knowing much on this topic, it sounded somewhat academically rellevant, so that was the starting point for me. Turns out, I get pretty obsessed with the things I research (and I get annoyed when the sources are deleted from the internet). I gathered so many sources that I even thought the pattern’s background and anatomy could easily fill up my budgeted 30 pages for the theoretical part. (The practical part doubled the number up to 60 pages, even though theses in my uni have a recommended length of 30 pages).
But how come a pattern can take up so many pages?! The thing is… no pattern is a pattern without a context, and CQRS is full of it.
First researching days were pretty chaotical, many contemporary blogs/articles would cover only the pattern’s function, nothing near close to what I needed. So I decided to switch to a chronological search: starting with the bigger picture, the context that lead to its creation, how it evolved, how it got popular, how it looks in the current landscape, and ultimately what are the reasons to adopt it.
I even came up with a name: “The development and use of the CQRS pattern in software systems”. Fast forwarding to today, you can read it here.
My endeavour got a new addition shortly after I started: I found out there’s a book about CQRS, with authors from a very familiar corporation… if you guessed it was written by Microsoft’s people, you’d be right. Yet again, there’s no good day without Contoso company and Microsoft’s products (it’s in the name! Exploring CQRS and Event Sourcing. A journey into high scalability, availability, and maintainability with Windows Azure). Quite frankly, the book is free. Unfortunately for me at that time, it’s a long read, and I couldn’t manage to make mental room for their hypothetical architecture enoguh so I could understand what they were talking about. (I ended up skipping chapters and reading mostly the conclusions.)
It’s nice to have such a book; they put a lot of effort into it and even got the pattern’s creators involved. Give it a try if you have the time.
If you expected a long story, you’re in luck; I have tons to write about, including comments that didn’t make it into my thesis, but, disclaimer, for now this page is the first part in a series about CQRS (if I can even manage to go beyond 2 parts ;) ). In what follows, I’ll try and focus on the context and problems that lead to the pattern’s appearance.
An online scenius
The internet is a shape-shifting place. Sites and communities appear and disappear. Some platforms die of old age, others freeze in time because of inactivity (while their servers are being kept alive). Everything is part of the Internet’s uncertain lifecycle. Acknowledging the fact that information unless archived can be lost forever is the one and only argument to the statement that no amount of wishful thinking and sweaty search keyword combination can bring back the sites (or their information) that the Wayback Machine persists in their database. I’m saying this because the site where the most important author of the CQRS pattern often posted has been discontinued sometime in 2022. (Thankfully there was someone to archive it, but what if the Wayback Machine dies too? It would be a true disaster.)
Back to the pattern in question. Our story dates back to 2006, when Greg Young, the pattern’s initiator, mentioned he first talked about CQRS. We’d assume it was created one, two, maybe three years before, but actually, when I asked Udi Dahan in a private email, his response was this:
There was a kind of scenius at the time that came together with ALT.NET. Both myself and Greg were prominent members discussing the implications and applications of Domain Driven Design to “high scale” systems. I don’t remember the dates when all of those things were “first” discussed. I take some issue with the degree that Greg attributed it all to himself, but that’s water under the bridge.
The mention to alt.net might lead you to think it was a website, but actually, from what I understand, it was an Internet service provider that started in 1996. So, the pattern’s creation might not have dated few years prior to the official mention, but potentially 10 years prior. Either way, it’s not important to frustrate over its exact origin in time; there are concepts that can be attributed to one person (for example, Clean Architecture was introduced by Robert C. Martin), and there are situations that probably started in a group chat somewhere in the mists of time.
Of course, when researching a topic, finding out such a timeframe actually helps more (even if it’s more tedious) because you can find websites, especially blogs, that might have mentions of your topic of interest. In this case, a scenius offers many more points to start from, and by points I mean people. It’s impressive how many adepts had a blog or wrote in a magazine2. Compared to today, probably they weren’t in a competition with each other over who writes the most mainstream topics in the least amount of time. You have to admit it, you’ve seen bad articles written just for the sake of being written, without adding to the knowledge pool (I’m looking at you, Medium bloggers).
From my time while I researched this topic, I considered myself grateful for those people that shared their experience through quality blogs, free of charge. They even formed external group chats where the authors helped people on their issues3. Today I find that people’s perspective over sharing knowledge turned into a money-making culture. Many times I’ve seen modern-day blogs where surface-level or just enough information is given for free to let you form an idea, but if you want more than that, the author locks that knowledge behind a (sometimes expensive) paywall. Either by courses or by a paid articles, today it’s not the will to help people that gets them through the day; it’s the will to make more and more money. But I digress.
Anecdote: If you go through my thesis’ reference list, some blogs might have a comment section with useful (intact) conversations. In most cases, what unifies those comments is the one and only Greg Young arguing with people over their use cases and their understanding of the pattern. One confrontation I find amusing is between Greg and Vladimir Khorikov: link. Greg is more theoretical and analytical, while Vladimir gets straight to the implementation. In some cases, you can see comment sections as equally important due to their unpredictable, spontaneous nature.
If the pattern’s origins in time were pretty tricky, but ultimately, and with a bit of help from Udi Dahan, are now pinpointed, the rest is a reading task. Thankfully for you, while researching my thesis I have gathered a collection4 of most of the relevant links you can find on this topic.
On another note, I strongly recommend you to read the entire archive of blog posts from Greg Young, Udi Dahan, Martin Fowler, and Mike Mogosanu. In your lecture you’ll find that each and every one of them is versed in CQRS and many something elses.
One something else is Domain-Driven Design (DDD), and, like I wrote in my thesis, “the origins of CQRS are firmly rooted in the application of DDD to large-scale systems”. That is because large-scale systems benefit from DDD to separate domains and interactions between them, and the domains benefit from CQRS’ fine-grained control and separation of concerns.
DDD is not exactly the methodology you want to jump into if you’re new to the software systems architecture & design. I myself didn’t grasp everything clearly from the get-go. But at least I can lay out some concepts that will come in handy later.
Before anything, you have to acknowledge that DDD has nothing to do with the implementation details or the programming languages you’re using. I know it’s hard to transition from the programmer’s point of view, especially if you’re new to system’s design, but it’s the only way.
So, a big application is always split apart either phisically or logically for various reasons, that’s why most DDD practitioners start with the bigger picture, called a domain. This domain is populated by entities (not objects!) that hold meanings and are able to interact with each other. An ubiquitous language is established between the entities, the team members and the users/systems that interact with the domain. Zooming in, this conceptual domain is implemented in each component of the system (if it has to be split apart phisically for example) in a domain model that conforms to a bounded context unique to the system component it’s implemented in. Entities can have different meanings across bounded contexts and sometimes represent different concepts altogether (Mike Mogosanu wrote a good example: Marketing can say Customer and Accounting can say Payer but they can both mean the same thing for the business as a whole).
Of course, my explanation of DDD is incomplete5, but for the rest to come it’ll do.
Another something else is Event Sourcing (ES). It’s a complicated pattern, and you can get away without it well beyond the incipient-to-intermediate stages of your programmer career. ES basically transforms your domain object’s state persisted in your database in a series of additive events. Each event has a precise timestamp, so any errors resulted from feeding stale data to the users enable you to easily discard the erroneous change (by adding another event). Lots of mechanisms like snapshotting and synchronization routes can be added, but I digress.
The reason most authors include ES in their speech is because if you apply ES in a system, you are better off if you integrate CQRS as well6. It’s about the separation of concerns that happens when you transfer data. CQRS provides two one-way paths: a write/command path to alter the state of the domain and a read/query path to retrieve information from the domain. In the case of ES, the command path adds events to a domain store, and the query path takes events from the store to construct the domain object7.
Greg Young’s stereotypical architecture
We’re still not done with the incipient stages, and thankfully Greg Young wrote an invaluable document about the problems that go away when CQRS is applied. The document is located here: https://cqrs.wordpress.com/wp-content/uploads/2010/11/cqrs_documents.pdf
It’s a long read, so I feel the urge to summarize.
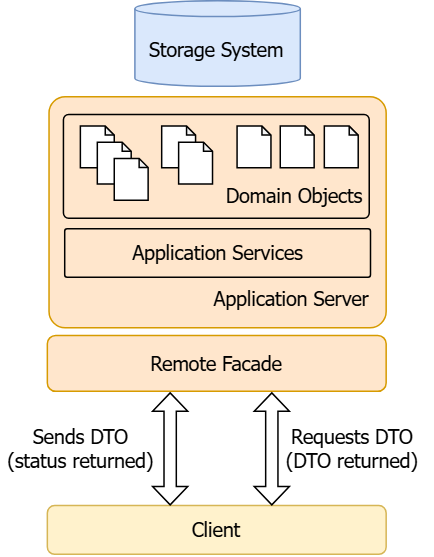
It is a simple architecture, and it doesn’t leave much room for improvement. Before you ask, yes, it’s how the author portrayed it 14 years ago; maybe they viewed it differently back then, and I’m with you if you say you don’t get what the stack of rectangles in the image do. The gist is that every layer transfers data—in this case domain objects of sorts (DDD is not applied here)—from the client to the database without much interaction apart from validation. The existence of domain objects and the lack of interaction might lead us to think that we work with an anti-pattern called an anemic domain, but it’s not the case.
The catch comes when you look at the behavior, and you realize that there is hardly any behavior on these objects, making them little more than bags of getters and setters. […] Instead there are a set of service objects which capture all of the domain logic. These services live on top of the domain model and use the domain model for data
In this architecture, the service objects apply little to no domain logic: here the services themselves are really just mapping DTO’s to domain objects, a match made in heaven, right?
In this case a large amount of business logic is not existing in the domain at all, nor in the Application Server, it may exist on the client but more likely it exists on either pieces of paper in a manual or in the heads of the people using the system. […] This is far worse than the creation of an anemic model, this is the creation of a glorified excel spreadsheet.
Solutions… anybody?
Yeah, scrap this architecture. Get away from the CRUD mindset, think about your domain, and rethink the interactions between the users and the domain entities.
The first and third points have the same solution: create task-based UIs and use CQRS to classify tasks in commands or queries. For now, simple granular interactions are your best starting point. In part 2, I’ll write about the flavours of CQRS and how and why changes may avalanche in development. The second point requires you to introduce the DDD methodology in your project; it’s not a light decision, and you can create partial adaptations of it, depending on your application’s needs.
What is CQRS again?
Indeed, I’ve done a poor job of describing what CQRS actually is. Most people start with citing the first paragraph from Greg Young’s page: CQRS, Task Based UIs, Event Sourcing agh! but I won’t. I’d do an injustice to the blog post if I picked only the essentials (and devoid you of an 2008 blog aesthetic); you’re better off reading it in its entirety.\
To recap, CQRS was born in spite of CRUD, with the help of DDD, and starting to shift software from implementation first to domain first.
While CRUD provides basic data manipulation functions, in complex systems, this paradigm does not capture the intent or behaviour of operations outside of an external user manual. You can already guess that the issue is the data centric focus of the early software; it began with modelling the data and then identifying processes to act on that data. This happened in part because software architects started in a bottom-up manner by creating a relational data model that travelled up through the application in order to be consumed.
With CQRS you are using different pathways and data models for the same data. One of the pattern’s largest possible benefits is that it recognises the different architectural properties when dealing with commands and queries. Splitting the application into two sides also means a change in access patterns: commands might be less frequent than queries, so asymmetry often becomes a reality (which you can exploit).
But WHAT IS CQRS?! I can’t really hear these four letters in this order without thinking about my 9 months of constantly being around these concepts; I feel different when this subject is on the table; I almost get shivers down my spine. Anyway…
It’s a pattern with a twist. Command Query Responsibility Segregation surely separates commands from queries, and it surely comes with a lot of baggage (and/or trouble), but if your use case fits, you can end up with a whole set of real benefits that will be revealed mostly in the next part.
Data is precious, and handling data is what makes programmers rich. By induction, you can get richer if you handle more data. And CQRS can help you handle more data more easily. The pattern’s intrinsic quality lies in the separation of read concerns from write concerns, while its extrinsic quality is the variability it enables. These qualities create an amalgam which derives aspects that can be adjusted independently to suit your use cases, the whole being better than the sum of its parts kind of thing.
So what don’t they understand about CQRS and where is it everywhere?
Alright, maybe I dramatize a bit. I find there are two aspects that don’t match with the initial idea of this pattern.
The first one is about classification into architectural patterns. I see in the newer blog posts this classification, but I disagree. CQRS is more of a concept than a pattern. We sure define patterns as solutions to frequent problems, and we (the programmers) instantly jump into code to grasp the good vs. the bad implementation. In this case, the solution CQRS gives us can be adapted in many other places than just in code. And as the avid programmers see mostly in black and white, in good or bad implementations8, CQRS is in a gray area that teaches us to think more “outside the box” (I mean outside the class, for my OOP fellas).
Plus a note: CQRS is not a top-level architecture (eg. any multilayer architecture).
The second aspect that bothers me (but mostly Greg Young ever since the pattern’s inception) is about Event Sourcing. There is a symbiotic relationship between CQRS and Event Sourcing, as Greg Young states, yet there are some popular blog posts that jump straight into both of them without a clear, sane separation.
Not even Microsoft seems to distinguish between nuances, at least some of their employees. In their CQRS-related article, the author uses such poor wording that makes me believe it’s common among “bloggers” to propagate surface-level knowledge: “Some implementations of CQRS use the Event Sourcing pattern”—it’s not the CQRS that uses Event Sourcing, it’s the Event Sourcing that uses CQRS; it’s the purest form of piggybacking (more on this in part 2).
And then there is a certain group of “bloggers” that reiterate what is already known, in digestible and simple terms, maybe even written by AI chatbots entirely. I think they’re inevitable in this context: an online scenius is hard to track and the worst part is that it takes time to search & read everything and then it takes even more time to piece things together. It’s no wonder why surface-level knowledge proliferates in the online space; if this is good or bad, it’s up to you.
On this topic: Part 2
Edit from May 2025: part 2 won’t come. I realized late that I first need to work out on my writing, my thesis was poorly written (at least by my standards) and I have to deal with adult livelihood now, somehow. This blog was a project I wanted for a long time to set up and finally got done while I was job hunting in 2024; the main content I wanted to post at that time was CQRS stuff in hope it would be easier to expose in blog-form some CQRS stuff I wrote in my thesis, but second book syndrome is real and I’m fricking stuck. Apologies.
Notes
From Romanian: “demonstrarea rolului CQRS”; now you know where I’m from. (Don’t even think to associate the previous italic word with my unfortunate birthplace.) ↩
For example MSDN Magazine https://learn.microsoft.com/en-us/archive/msdn-magazine/msdn-magazine-issues ↩
See Google Groups: https://groups.google.com/g/dddcqrs ↩
If you can’t click the link: https://github.com/filipvalentin/useful_links/blob/main/thesis_references_links.md ↩
Here are more resources on DDD: https://github.com/ddd-crew. You can also check Eric Evan’s book on DDD. ↩
Greg Young wrote “They are certainly two different patterns but I believe that it is a relatively rare case where two patterns share a symbiotic relationship.” https://web.archive.org/web/20130225221336/http://codebetter.com/gregyoung/2010/02/13/cqrs-and-event-sourcing/ ↩
Here intervene snapshots and query repositories. Big systems end up with lots of events and query requests. It is almost free to alter the state of the domain: you just add an event. On the other hand, it becomes increasingly slower to construct the domain object’s state when a query is requested. You can get away from such performance penalty by using snapshots to compact the object’s state; consequently, new events are based on the latest snapshot. Once a day, an automatic routine compacts the events into a new snapshot. It’s unfeasible to perform snapshots more regularly; you would have applied ES for nothing. But what if repeated queries are requested? In such case, you store the constructed object’s state in a (temporary) query repository. How you manage the cache invalidation problem is up to you. ↩
Experienced developers are more than just programmers, they can design architectures while being fully aware of the nuances that appear from the design stage all the way up to implementation. They would see CQRS as the concept it is, not just a pattern implemented in code. ↩